Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Inhoud geleverd door LessWrong. Alle podcastinhoud, inclusief afleveringen, afbeeldingen en podcastbeschrijvingen, wordt rechtstreeks geüpload en geleverd door LessWrong of hun podcastplatformpartner. Als u denkt dat iemand uw auteursrechtelijk beschermde werk zonder uw toestemming gebruikt, kunt u het hier beschreven proces https://nl.player.fm/legal volgen.
Overeenkomstig met LessWrong (Curated & Popular)
We help founders make something people want.
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Material is a weekly discussion about the Google and Android universe. Your intrepid hosts try to answer the question, “What holds up the digital world?” The answer, so far, is that it’s Google all the way down. Hosted by Andy Ihnatko and Florence Ion.
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Welcome to Hands-On Tech, where host Mikah Sargent turns tech troubles into tech triumphs. Each episode zooms in on a specific theme, unpacking listener questions with expert analysis and easy-to-follow advice. From decoding the latest gadgets to simplifying everyday tech, Mikah's got you covered. Submit your tech queries through email at HOT@twit.tv or via TWiT's social media. You might hear your question answered on air! And keep an ear out for guest experts who drop by to share their spec ...
…
continue reading
Player FM - Podcast-app
Ga offline met de app Player FM !
Ga offline met de app Player FM !

))
“Current safety training techniques do not fully transfer to the agent setting” by Simon Lermen, Govind Pimpale
Manage episode 449300751 series 3364760
Inhoud geleverd door LessWrong. Alle podcastinhoud, inclusief afleveringen, afbeeldingen en podcastbeschrijvingen, wordt rechtstreeks geüpload en geleverd door LessWrong of hun podcastplatformpartner. Als u denkt dat iemand uw auteursrechtelijk beschermde werk zonder uw toestemming gebruikt, kunt u het hier beschreven proces https://nl.player.fm/legal volgen.
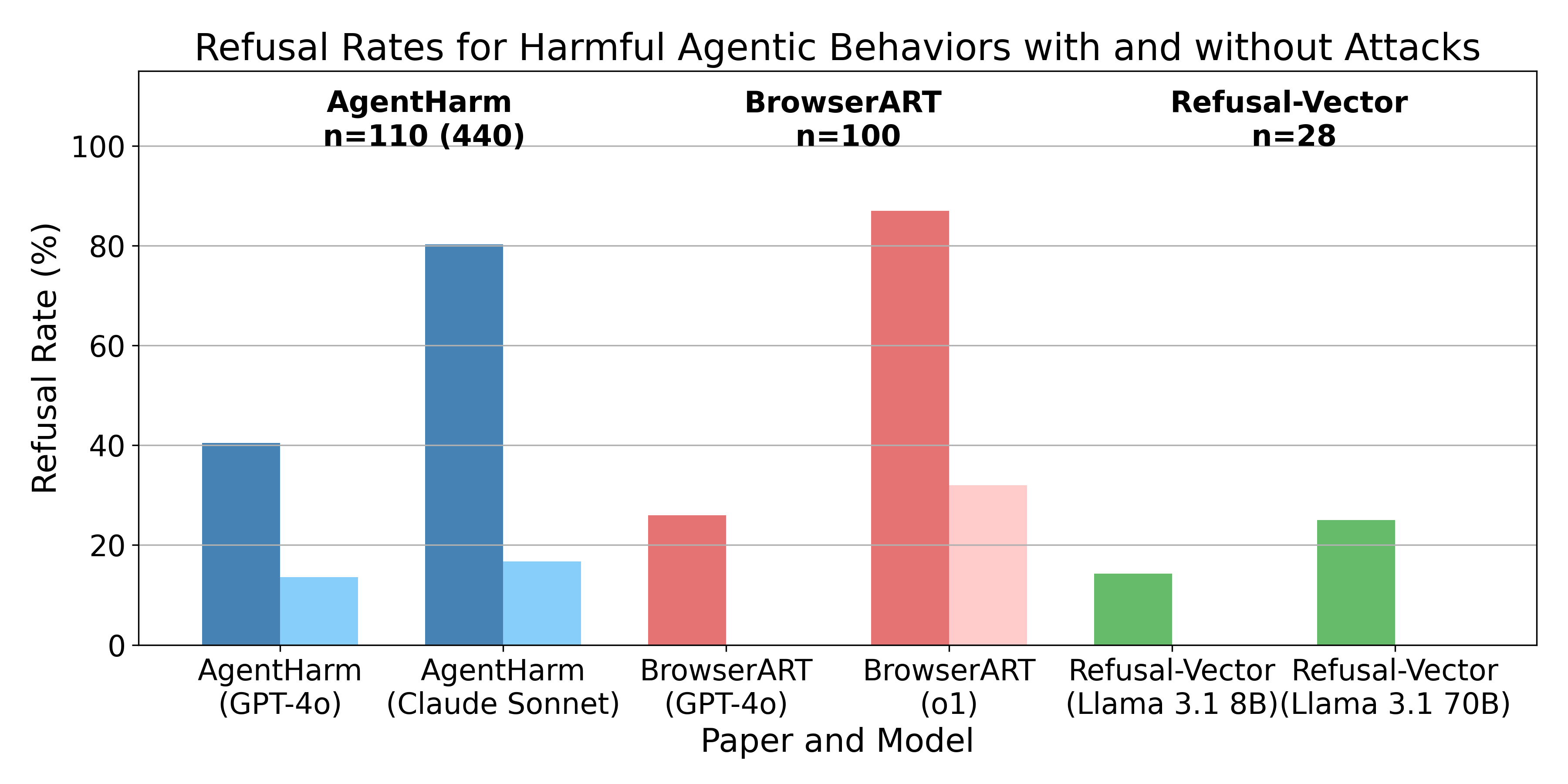
TL;DR: I'm presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
- Refusal-Trained LLMs Are Easily Jailbroken As Browser Agents
- Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.378 afleveringen
Manage episode 449300751 series 3364760
Inhoud geleverd door LessWrong. Alle podcastinhoud, inclusief afleveringen, afbeeldingen en podcastbeschrijvingen, wordt rechtstreeks geüpload en geleverd door LessWrong of hun podcastplatformpartner. Als u denkt dat iemand uw auteursrechtelijk beschermde werk zonder uw toestemming gebruikt, kunt u het hier beschreven proces https://nl.player.fm/legal volgen.
TL;DR: I'm presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
- Refusal-Trained LLMs Are Easily Jailbroken As Browser Agents
- Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.378 afleveringen
كل الحلقات
×Welkom op Player FM!
Player FM scant het web op podcasts van hoge kwaliteit waarvan u nu kunt genieten. Het is de beste podcast-app en werkt op Android, iPhone en internet. Aanmelden om abonnementen op verschillende apparaten te synchroniseren.
Overeenkomstig met LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
We help founders make something people want.
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Material is a weekly discussion about the Google and Android universe. Your intrepid hosts try to answer the question, “What holds up the digital world?” The answer, so far, is that it’s Google all the way down. Hosted by Andy Ihnatko and Florence Ion.
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Welcome to Hands-On Tech, where host Mikah Sargent turns tech troubles into tech triumphs. Each episode zooms in on a specific theme, unpacking listener questions with expert analysis and easy-to-follow advice. From decoding the latest gadgets to simplifying everyday tech, Mikah's got you covered. Submit your tech queries through email at HOT@twit.tv or via TWiT's social media. You might hear your question answered on air! And keep an ear out for guest experts who drop by to share their spec ...
…
continue reading
Player FM - Podcast-app
Ga offline met de app Player FM !
Ga offline met de app Player FM !



