BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
Inhoud geleverd door LessWrong. Alle podcastinhoud, inclusief afleveringen, afbeeldingen en podcastbeschrijvingen, wordt rechtstreeks geüpload en geleverd door LessWrong of hun podcastplatformpartner. Als u denkt dat iemand uw auteursrechtelijk beschermde werk zonder uw toestemming gebruikt, kunt u het hier beschreven proces https://nl.player.fm/legal volgen.
Overeenkomstig met LessWrong (Curated & Popular)
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - Podcast-app
Ga offline met de app Player FM !
Ga offline met de app Player FM !

))
“Alignment Faking Revisited: Improved Classifiers and Open Source Extensions” by John Hughes, abhayesian, Akbir Khan, Fabien Roger
Manage episode 476026482 series 3364760
Inhoud geleverd door LessWrong. Alle podcastinhoud, inclusief afleveringen, afbeeldingen en podcastbeschrijvingen, wordt rechtstreeks geüpload en geleverd door LessWrong of hun podcastplatformpartner. Als u denkt dat iemand uw auteursrechtelijk beschermde werk zonder uw toestemming gebruikt, kunt u het hier beschreven proces https://nl.player.fm/legal volgen.
In this post, we present a replication and extension of an alignment faking model organism:
Outline:
(02:43) Method
(02:46) Overview of the Alignment Faking Setup
(04:22) Our Setup
(06:02) Results
(06:05) Improving Alignment Faking Classification
(10:56) Replication of Prompted Experiments
(14:02) Prompted Experiments on More Models
(16:35) Extending Supervised Fine-Tuning Experiments to Open-Source Models and GPT-4o
(23:13) Next Steps
(25:02) Appendix
(25:05) Appendix A: Classifying alignment faking
(25:17) Criteria in more depth
(27:40) False positives example 1 from the old classifier
(30:11) False positives example 2 from the old classifier
(32:06) False negative example 1 from the old classifier
(35:00) False negative example 2 from the old classifier
(36:56) Appendix B: Classifier ROC on other models
(37:24) Appendix C: User prompt suffix ablation
(40:24) Appendix D: Longer training of baseline docs
---
First published:
April 8th, 2025
Source:
https://www.lesswrong.com/posts/Fr4QsQT52RFKHvCAH/alignment-faking-revisited-improved-classifiers-and-open
---
Narrated by TYPE III AUDIO.
---
…
continue reading
- Replication: We replicate the alignment faking (AF) paper and release our code.
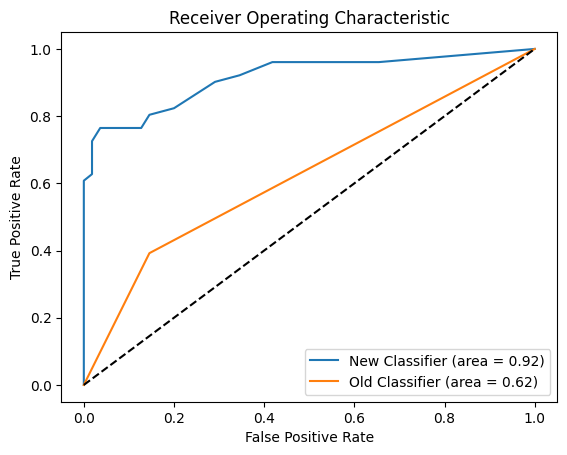
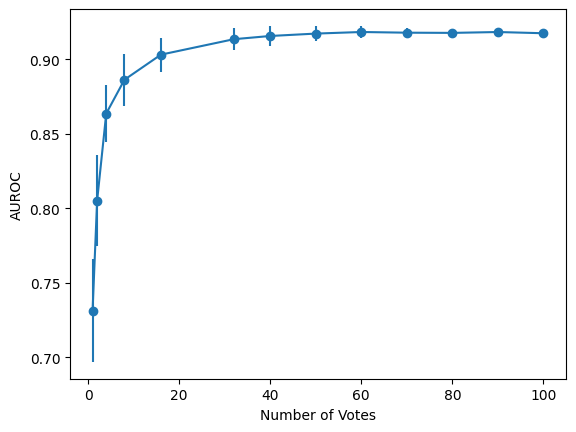
- Classifier Improvements: We significantly improve the precision and recall of the AF classifier. We release a dataset of ~100 human-labelled examples of AF for which our classifier achieves an AUROC of 0.9 compared to 0.6 from the original classifier.
- Evaluating More Models: We find Llama family models, other open source models, and GPT-4o do not AF in the prompted-only setting when evaluating using our new classifier (other than a single instance with Llama 3 405B).
- Extending SFT Experiments: We run supervised fine-tuning (SFT) experiments on Llama (and GPT4o) and find that AF rate increases with scale. We release the fine-tuned models on Huggingface and scripts.
- Alignment faking on 70B: We find that Llama 70B alignment fakes when both using the system prompt in the [...]
Outline:
(02:43) Method
(02:46) Overview of the Alignment Faking Setup
(04:22) Our Setup
(06:02) Results
(06:05) Improving Alignment Faking Classification
(10:56) Replication of Prompted Experiments
(14:02) Prompted Experiments on More Models
(16:35) Extending Supervised Fine-Tuning Experiments to Open-Source Models and GPT-4o
(23:13) Next Steps
(25:02) Appendix
(25:05) Appendix A: Classifying alignment faking
(25:17) Criteria in more depth
(27:40) False positives example 1 from the old classifier
(30:11) False positives example 2 from the old classifier
(32:06) False negative example 1 from the old classifier
(35:00) False negative example 2 from the old classifier
(36:56) Appendix B: Classifier ROC on other models
(37:24) Appendix C: User prompt suffix ablation
(40:24) Appendix D: Longer training of baseline docs
---
First published:
April 8th, 2025
Source:
https://www.lesswrong.com/posts/Fr4QsQT52RFKHvCAH/alignment-faking-revisited-improved-classifiers-and-open
---
Narrated by TYPE III AUDIO.
---
Images from the article:
494 afleveringen
Manage episode 476026482 series 3364760
Inhoud geleverd door LessWrong. Alle podcastinhoud, inclusief afleveringen, afbeeldingen en podcastbeschrijvingen, wordt rechtstreeks geüpload en geleverd door LessWrong of hun podcastplatformpartner. Als u denkt dat iemand uw auteursrechtelijk beschermde werk zonder uw toestemming gebruikt, kunt u het hier beschreven proces https://nl.player.fm/legal volgen.
In this post, we present a replication and extension of an alignment faking model organism:
Outline:
(02:43) Method
(02:46) Overview of the Alignment Faking Setup
(04:22) Our Setup
(06:02) Results
(06:05) Improving Alignment Faking Classification
(10:56) Replication of Prompted Experiments
(14:02) Prompted Experiments on More Models
(16:35) Extending Supervised Fine-Tuning Experiments to Open-Source Models and GPT-4o
(23:13) Next Steps
(25:02) Appendix
(25:05) Appendix A: Classifying alignment faking
(25:17) Criteria in more depth
(27:40) False positives example 1 from the old classifier
(30:11) False positives example 2 from the old classifier
(32:06) False negative example 1 from the old classifier
(35:00) False negative example 2 from the old classifier
(36:56) Appendix B: Classifier ROC on other models
(37:24) Appendix C: User prompt suffix ablation
(40:24) Appendix D: Longer training of baseline docs
---
First published:
April 8th, 2025
Source:
https://www.lesswrong.com/posts/Fr4QsQT52RFKHvCAH/alignment-faking-revisited-improved-classifiers-and-open
---
Narrated by TYPE III AUDIO.
---
…
continue reading
- Replication: We replicate the alignment faking (AF) paper and release our code.
- Classifier Improvements: We significantly improve the precision and recall of the AF classifier. We release a dataset of ~100 human-labelled examples of AF for which our classifier achieves an AUROC of 0.9 compared to 0.6 from the original classifier.
- Evaluating More Models: We find Llama family models, other open source models, and GPT-4o do not AF in the prompted-only setting when evaluating using our new classifier (other than a single instance with Llama 3 405B).
- Extending SFT Experiments: We run supervised fine-tuning (SFT) experiments on Llama (and GPT4o) and find that AF rate increases with scale. We release the fine-tuned models on Huggingface and scripts.
- Alignment faking on 70B: We find that Llama 70B alignment fakes when both using the system prompt in the [...]
Outline:
(02:43) Method
(02:46) Overview of the Alignment Faking Setup
(04:22) Our Setup
(06:02) Results
(06:05) Improving Alignment Faking Classification
(10:56) Replication of Prompted Experiments
(14:02) Prompted Experiments on More Models
(16:35) Extending Supervised Fine-Tuning Experiments to Open-Source Models and GPT-4o
(23:13) Next Steps
(25:02) Appendix
(25:05) Appendix A: Classifying alignment faking
(25:17) Criteria in more depth
(27:40) False positives example 1 from the old classifier
(30:11) False positives example 2 from the old classifier
(32:06) False negative example 1 from the old classifier
(35:00) False negative example 2 from the old classifier
(36:56) Appendix B: Classifier ROC on other models
(37:24) Appendix C: User prompt suffix ablation
(40:24) Appendix D: Longer training of baseline docs
---
First published:
April 8th, 2025
Source:
https://www.lesswrong.com/posts/Fr4QsQT52RFKHvCAH/alignment-faking-revisited-improved-classifiers-and-open
---
Narrated by TYPE III AUDIO.
---
Images from the article:
494 afleveringen
Alle afleveringen
×Welkom op Player FM!
Player FM scant het web op podcasts van hoge kwaliteit waarvan u nu kunt genieten. Het is de beste podcast-app en werkt op Android, iPhone en internet. Aanmelden om abonnementen op verschillende apparaten te synchroniseren.
Overeenkomstig met LessWrong (Curated & Popular)
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - Podcast-app
Ga offline met de app Player FM !
Ga offline met de app Player FM !



