
))
From API to AGI: Structured Outputs, OpenAI API platform and O1 Q&A — with Michelle Pokrass & OpenAI Devrel + Strawberry team
Manage episode 439806175 series 3451473
Inhoud geleverd door swyx & Alessio. Alle podcastinhoud, inclusief afleveringen, afbeeldingen en podcastbeschrijvingen, wordt rechtstreeks geüpload en geleverd door swyx & Alessio of hun podcastplatformpartner. Als u denkt dat iemand uw auteursrechtelijk beschermde werk zonder uw toestemming gebruikt, kunt u het hier beschreven proces https://nl.player.fm/legal volgen.
Congrats to Damien on successfully running AI Engineer London! See our community page and the Latent Space Discord for all upcoming events.
This podcast came together in a far more convoluted way than usual, but happens to result in a tight 2 hours covering the ENTIRE OpenAI product suite across ChatGPT-latest, GPT-4o and the new o1 models, and how they are delivered to AI Engineers in the API via the new Structured Output mode, Assistants API, client SDKs, upcoming Voice Mode API, Finetuning/Vision/Whisper/Batch/Admin/Audit APIs, and everything else you need to know to be up to speed in September 2024.
This podcast has two parts: the first hour is a regular, well edited, podcast on 4o, Structured Outputs, and the rest of the OpenAI API platform. The second was a rushed, noisy, hastily cobbled together recap of the top takeaways from the o1 model release from yesterday and today.
Building AGI with Structured Outputs — Michelle Pokrass of OpenAI API team
Michelle Pokrass built massively scalable platforms at Google, Stripe, Coinbase and Clubhouse, and now leads the API Platform at Open AI. She joins us today to talk about why structured output is such an important modality for AI Engineers that Open AI has now trained and engineered a Structured Output mode with 100% reliable JSON schema adherence.
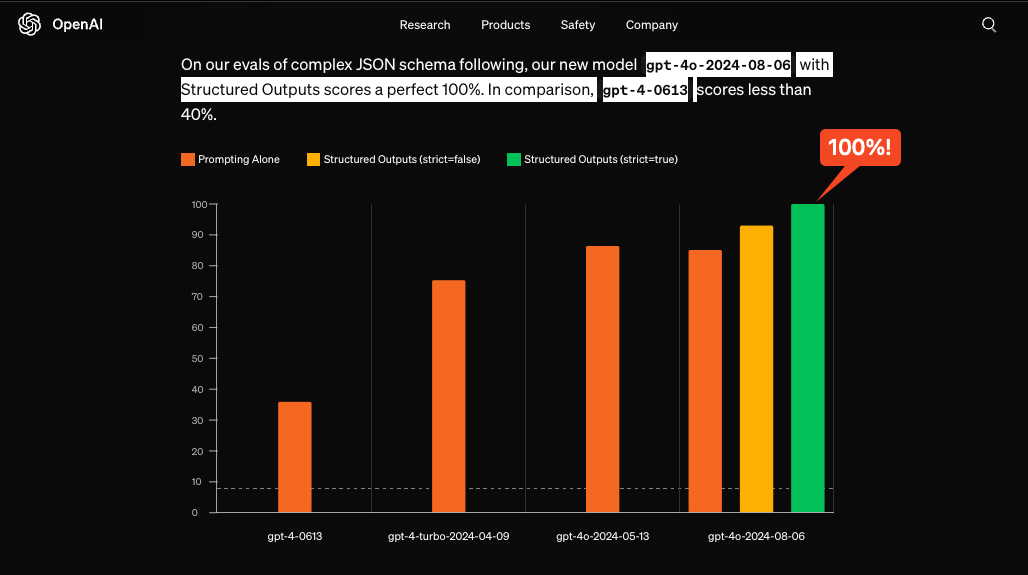
To understand why this is important, a bit of history is important:
June 2023 when OpenAI first added a "function calling" capability to GPT-4-0613 and GPT 3.5 Turbo 0613 (our podcast/writeup here)
November 2023’s OpenAI Dev Day (our podcast/writeup here) where the team shipped JSON Mode, a simpler schema-less JSON output mode that nevertheless became more popular because function calling often failed to match the JSON schema given by developers.
Meanwhile, in open source, many solutions arose, including
Instructor (our pod with Jason here)
LangChain (our pod with Harrison here, and he is returning next as a guest co-host)
Outlines (Remi Louf’s talk at AI Engineer here)
Llama.cpp’s constrained grammar sampling using GGML-BNF
April 2024: OpenAI started implementing constrained sampling with a new `
tool_choice: required` parameter in the APIAugust 2024: the new Structured Output mode, co-led by Michelle
Sept 2024: Gemini shipped Structured Outputs as well
We sat down with Michelle to talk through every part of the process, as well as quizzing her for updates on everything else the API team has shipped in the past year, from the Assistants API, to Prompt Caching, GPT4 Vision, Whisper, the upcoming Advanced Voice Mode API, OpenAI Enterprise features, and why every Waterloo grad seems to be a cracked engineer.
Part 1 Timestamps and Transcript
[00:00:42] Episode Intro from Suno
[00:03:34] Michelle's Path to OpenAI
[00:12:20] Scaling ChatGPT
[00:13:20] Releasing Structured Output
[00:16:17] Structured Outputs vs Function Calling
[00:19:42] JSON Schema and Constrained Grammar
[00:20:45] OpenAI API team
[00:21:32] Structured Output Refusal Field
[00:24:23] ChatML issues
[00:26:20] Function Calling Evals
[00:28:34] Parallel Function Calling
[00:29:30] Increased Latency
[00:30:28] Prompt/Schema Caching
[00:30:50] Building Agents with Structured Outputs: from API to AGI
[00:31:52] Assistants API
[00:34:00] Use cases for Structured Output
[00:37:45] Prompting Structured Output
[00:39:44] Benchmarking Prompting for Structured Outputs
[00:41:50] Structured Outputs Roadmap
[00:43:37] Model Selection vs GPT4 Finetuning
[00:46:56] Is Prompt Engineering Dead?
[00:47:29] 2 models: ChatGPT Latest vs GPT 4o August
[00:50:24] Why API => AGI
[00:52:40] Dev Day
[00:54:20] Assistants API Roadmap
[00:56:14] Model Reproducibility/Determinism issues
[00:57:53] Tiering and Rate Limiting
[00:59:26] OpenAI vs Ops Startups
[01:01:06] Batch API
[01:02:54] Vision
[01:04:42] Whisper
[01:07:21] Voice Mode API
[01:08:10] Enterprise: Admin/Audit Log APIs
[01:09:02] Waterloo grads
[01:10:49] Books
[01:11:57] Cognitive Biases
[01:13:25] Are LLMs Econs?
[01:13:49] Hiring at OpenAI
Emergency O1 Meetup — OpenAI DevRel + Strawberry team
the following is our writeup from AINews, which so far stands the test of time.
o1, aka Strawberry, aka Q*, is finally out! There are two models we can use today: o1-preview (the bigger one priced at $15 in / $60 out) and o1-mini (the STEM-reasoning focused distillation priced at $3 in/$12 out) - and the main o1 model is still in training. This caused a little bit of confusion.

There are a raft of relevant links, so don’t miss:
the o1 Hub
the o1-mini blogpost
the o1 system card
the platform docs
the o1 team video and contributors list (twitter)
Inline with the many, many leaks leading up to today, the core story is longer “test-time inference” aka longer step by step responses - in the ChatGPT app this shows up as a new “thinking” step that you can click to expand for reasoning traces, even though, controversially, they are hidden from you (interesting conflict of interest…):

Under the hood, o1 is trained for adding new reasoning tokens - which you pay for, and OpenAI has accordingly extended the output token limit to >30k tokens (incidentally this is also why a number of API parameters from the other models like temperature and role and tool calling and streaming, but especially max_tokens is no longer supported).

The evals are exceptional. OpenAI o1:
ranks in the 89th percentile on competitive programming questions (Codeforces),
places among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME),
and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA).

You are used to new models showing flattering charts, but there is one of note that you don’t see in many model announcements, that is probably the most important chart of all. Dr Jim Fan gets it right: we now have scaling laws for test time compute, and it looks like they scale loglinearly.

We unfortunately may never know the drivers of the reasoning improvements, but Jason Wei shared some hints:

Usually the big model gets all the accolades, but notably many are calling out the performance of o1-mini for its size (smaller than gpt 4o), so do not miss that.

Part 2 Timestamps
[01:15:01] O1 transition
[01:16:07] O1 Meetup Recording
[01:38:38] OpenAI Friday AMA recap
[01:44:47] Q&A Part 2
[01:50:28] O1 Demos


Demo Videos to be posted shortly
95 afleveringen



